Ein kurzer Crashkurs für den möglicherweise größten Innovations- und Technologietreiber unserer disruptiven Zeit
von Andreas Fuhrich
Wer dem KI-Diskurs folgt, stößt dabei häufig auf Begriffe, wie Machine Learning, Deep Learning, Neuronale Netze usw. Was es mit den verschiedenen Begriffen auf sich hat und worin sie sich unterscheiden, soll hier erläutert und an praxisnahen Beispielen verdeutlicht werden. Dabei kann und will der Text nicht mehr als ein grobes Verständnis vermitteln.
I. Grundlagen: Maschinelles Lernen und Entscheidungsbäume
Maschinelles Lernen ist ein Oberbegriff für die „künstliche“ Generierung von Wissen aus Erfahrung: Ein künstliches System lernt aus Beispielen und kann daraus Verallgemeinerungen ableiten. Dabei werden nicht einfach Beispiele auswendig gelernt, sondern Muster darin erkannt. Auf diese Weise kann ein System auch zuvor unbekannte Daten auf diese Muster durchsuchen und eine entsprechende Aussage treffen. Um dies zu ermöglichen, wurden verschiedene Modelle entwickelt, die sich nicht notwendigerweise ausschließen, sondern auch miteinander verknüpft werden können. Im Folgenden sollen einige dieser Modelle vorgestellt werden:
Entscheidungsbäume
Was ein Entscheidungsbaum ist, lässt sich am besten an Hand eines einfachen Beispiels erklären.
Angenommen ein Programm soll entscheiden, ob einem Kunden ein Kredit gewährt wird. Hierzu benötigt das Programm natürlich einige Daten: Hat der Kunde einen Schufaeintrag? Welches Einkommen hat er? Und welche Rücklagen?
Ein Entscheidungsbaum könnte dann wie unten dargestellt aussehen.
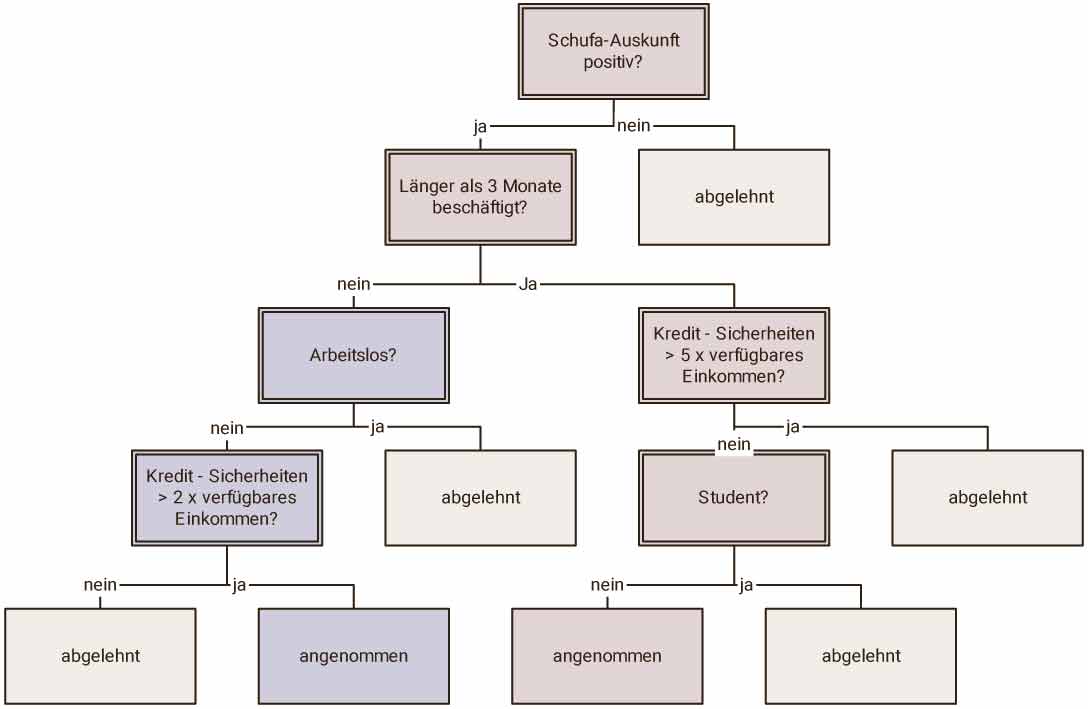
Zwar werden die meisten Software-Entwickler schon einmal so einen Baum programmiert haben, doch im Zusammenhang mit maschinellem Lernen passiert genau das nicht. Hier wird nun nicht direkt der Baum programmiert, sondern ein Algorithmus, der selbst automatisch Baumstrukturen aus einer Datenmenge generiert. Dazu ist es von entscheidender Bedeutung, dass ein geeigneter Datensatz mit verlässlichen Erfahrungswerten zum Entscheidungsproblem (der sogenannte Trainingsdatensatz) vorliegt. Das bedeutet, dass zu jedem Objekt des Trainingsdatensatzes die Klassifikation des Zielattributs bekannt sein muss. Bei jedem Induktionsschritt wird nun das Attribut gesucht, mit welchem sich die Trainingsdaten in diesem Schritt bezüglich des Zielattributs am besten klassifizieren lassen. Das ermittelte Attribut wird nun zur Aufteilung der Daten verwendet. Auf die so entstandenen Teilmengen wird die Prozedur rekursiv angewendet, bis in jeder Teilmenge nur noch Objekte mit einer Klassifikation enthalten sind. Am Ende ist ein Entscheidungsbaum entstanden, der das Erfahrungswissen des Trainingsdatensatzes in formalen Regeln beschreibt.
Die Bäume können nun zum automatischen Klassifizieren anderer Datensätze oder zum Interpretieren und Auswerten des entstandenen Regelwerks genutzt werden.
Entropie, Gini-Index und andere Maße für die Unreinheit von Daten bei Entscheidungsbäumen
In unserem konkreten Beispiel kann der Entscheidungsbaum dabei auch aus einem Datensatz hergeleitet worden sein, der längst nicht so eindeutig war. Z.B. kann es gut sein, dass früher auch Studenten Kredite erhielten und teilweise auch zurückzahlten. Es gibt also einen gewissen Grad an Unsicherheit, der mit der Regel verbunden ist, Studenten keine Kredite zu gewähren. Um zu bestimmen, wie geeignet ein bestimmtes Attribut zur Entscheidungsfindung ist, greift der Algorithmus auf statistische Verfahren wie Entropie oder Gini-Index zurück.
Vor und Nachteile von Entscheidungsbäumen
Der größte Vorteil von Entscheidungsbäumen ist ihre Transparenz. So ist für jeden Benutzer im Sinne einer White-Box-KI absolut nachvollziehbar, warum eine Entscheidung getroffen wurde. Entscheidungsbäume können gerade bei Datensätzen mit vielen Attributen den Anwendern einen zusätzlichen Erkenntnisgewinn hinsichtlich der Bedeutung der Attribute für eine bestimmte Entscheidung bieten. Die Transparenz der Entscheidung ermöglicht auch ein nachträgliches korrigieren: Beispielsweise könnte die KI erkannt haben, dass Frauen signifikant zuverlässiger Kredite zurückzahlen. Eine Information, die aus Gründen der Gleichstellung jedoch nicht benutzt werden darf. (Insbesondere bei der Risikoeinschätzung im Versicherungswesen spielt Vergleichbares tatsächlich eine Rolle)
Ein oft benannter Nachteil der Entscheidungsbäume hingegen ist die relativ geringe Klassifikationsgüte bei den meisten Klassifiaktionsproblemen aus der realen Welt, wie beispielsweise bei der Bilderkennung, wo der zu analysierende Input prinzipiell unendlich sein kann. Das bedeutet, dass durch die Bäume zwar für Menschen leicht nachvollziehbare Regeln erzeugt werden können, diese verständlichen Regeln aber für Klassifikationsprobleme der realen Welt oft nicht die bestmögliche Qualität besitzen.
Neuronale Netze am Beispiel von Text und Bilderkennung
Im Grunde soll ein neuronales Netz die Funktionsweise eines Gehirns nachahmen. Viele einzelne Neuronen verarbeiten durch Vernetzung Informationen. Je häufiger dabei bestimmte Neuronen mit anderen interagieren desto stärker wird die Verbindung.
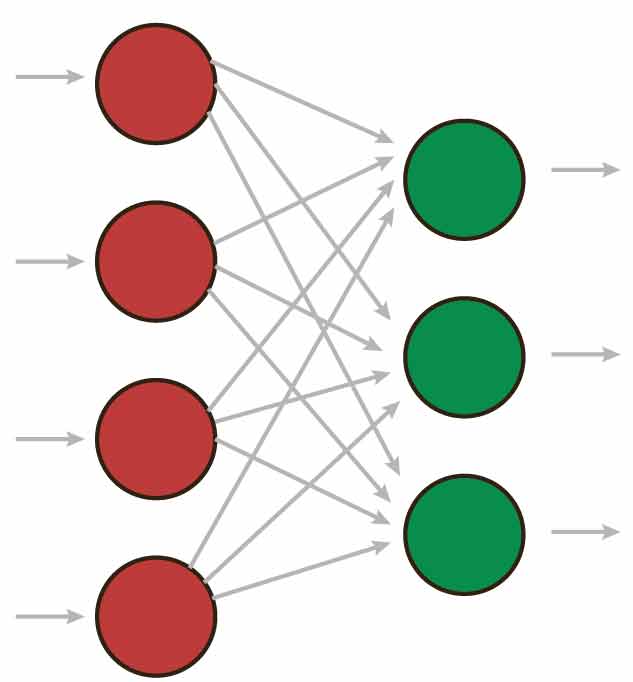
Ein einfaches neurales Netz besteht dabei aus nur zwei Schichten, Layer genannt, nämlich aus Input- und Output-Neuronen, die in der Informatik teilweise auch als Units bezeichnet werden.
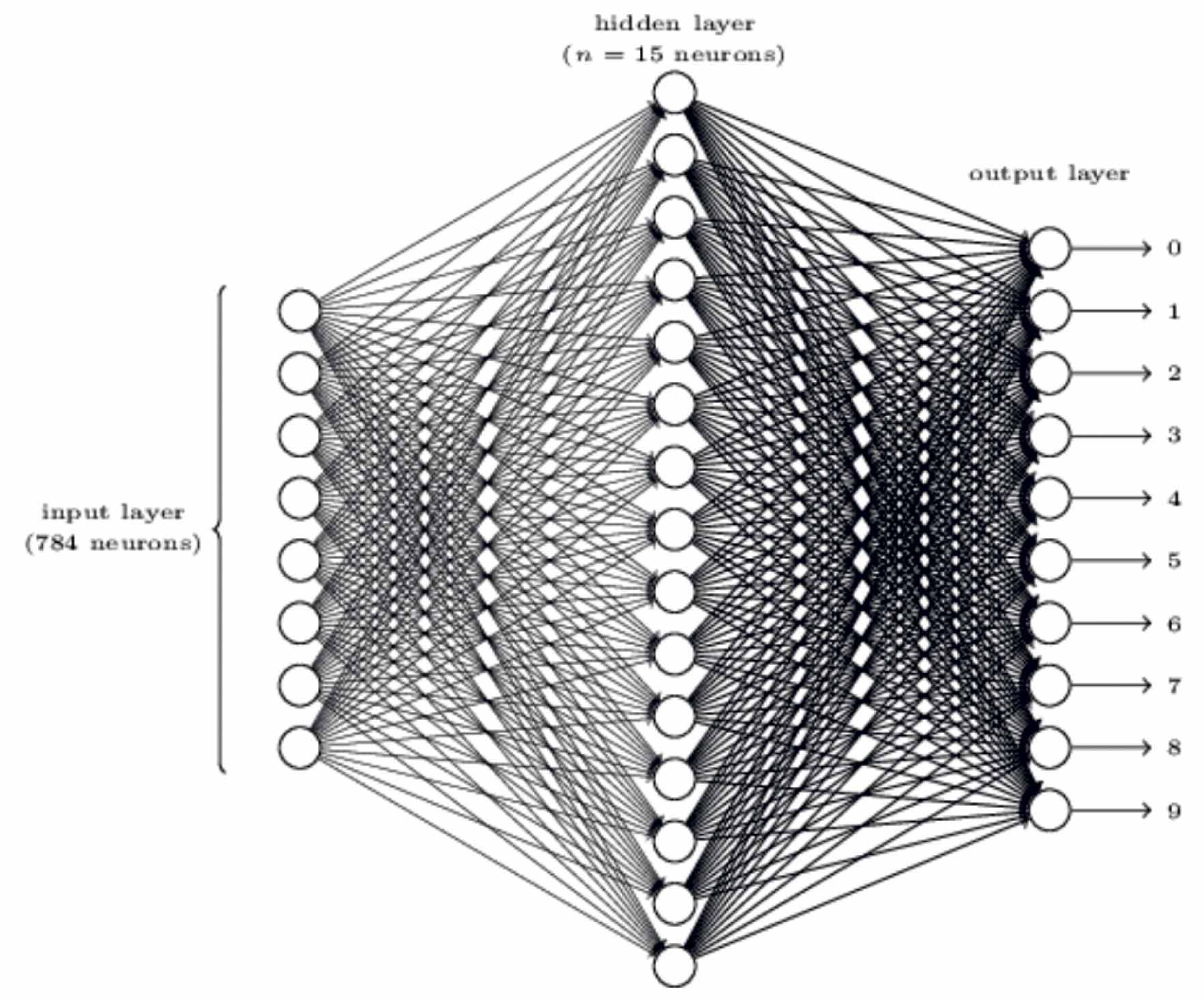
Hidden Layer
Sobald einem neuronalen Netzt zwischen Input- und Output-Unit eine Entscheidungsebene hinzugefügt wird, handelt es sich dabei um einen sogenannten Hidden Layer, der gleichermaßen als Abstraktionsebene fungiert.
Ein anschauliches Beispiel ist das automatische Erkennen von handgeschriebenen Ziffern. Bei einer Handgeschriebenen Ziffer in einem 64×64 Pixel großen Graustufen Bild, bietet es sich an, jedem Pixel eine Input-Unit zuzuordnen. Wir haben also 64×64=4096 Input-Units die einen Wert zwischen 0 (weiß) und 1 (schwarz) einnehmen, dabei können auch Graustufen in die Bewertung mit einbezogen werden, die für eine weniger starke Gewichtung sorgen. Da es zehn verschiedene Klassen gibt, denen eine Ziffer zugeordnet werden kann, nutzen wir eine Schicht aus zehn Output-Units. Das Bild wird entsprechend der Klasse zugeordnet, deren Output-unit aktiviert wird. Für den Hidden Layer könnte man zum Beispiel eine einfache Schicht aus 15 Neuronen wählen.
Die ersten vier Neuronen könnten sich zum Beispiel darauf spezialisiert haben, die Bestandteile einer Null zu erkennen und dann gemeinsam die entsprechende Output-Unit auslösen.
Ob dies Wirklich so ist, ist allerdings fraglich, da so ein neurales Netz für uns eine Black Box darstellt.
Deep Learning
Ziffern auf einem immer gleichgroßen Bild zu erkennen ist noch ein verhältnismäßig einfaches Beispiel. Wesentlich komplexer ist die Kategorisierung eines beliebigen Fotos. Damit ein neuronales Netz diese Aufgabe bewältigen kann, wird eine Vielzahl verdeckter Schichten hintereinander angeordnet. Je mehr Schichten, desto „deeper“ ist das Netzwerk, weswegen man in diesem Zusammenhang von Deep Learning redet.
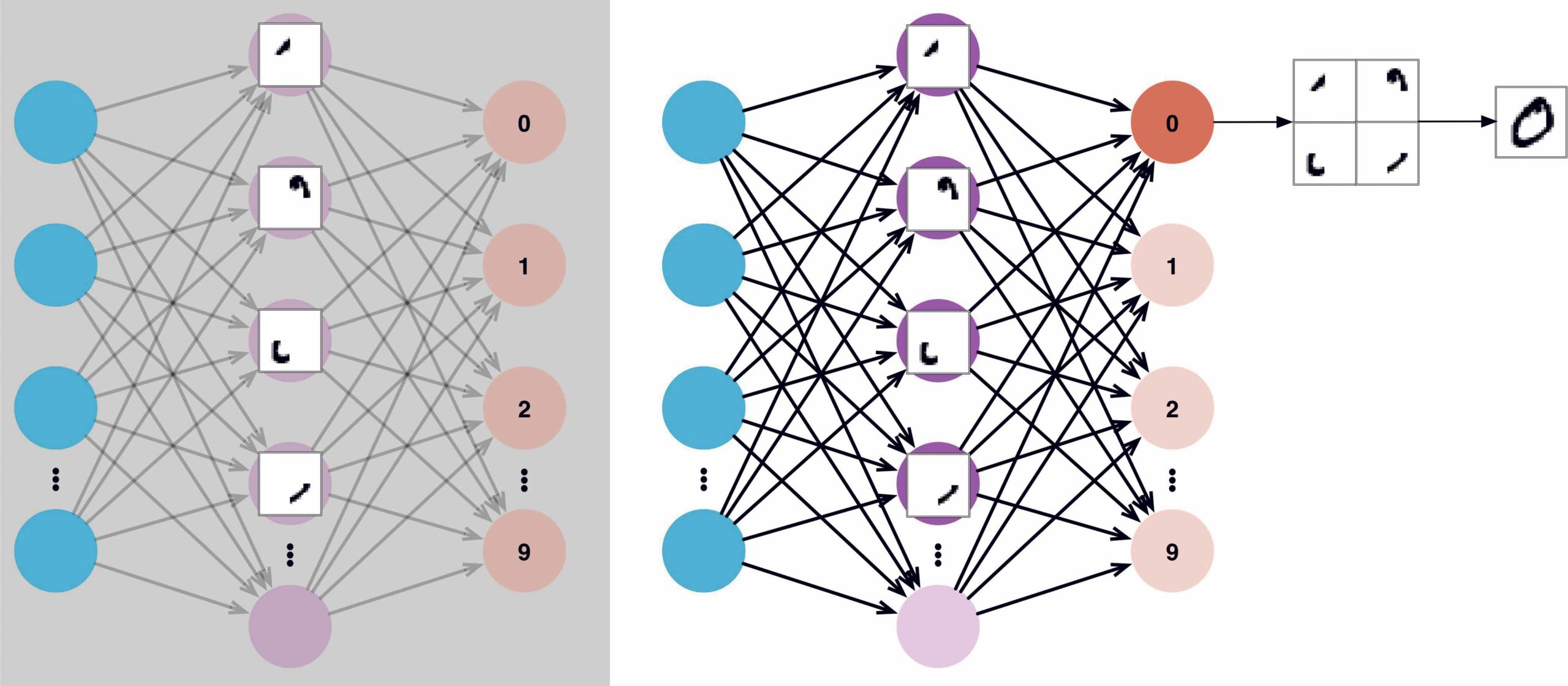
Bild re.:Eine handschriftliche 0 in einem Texterkennungsfeld sollte in unserem Beispiel die vier versteckten Neuronen triggern und das erste Output-Neuron „reizen“.
NLP und NLU
NLP – Natural Language Processing
Als NLP bezeichnet man ein Teilgebiet der Informatik, welches sich mit der Verarbeitung natürlicher Sprache durch eine künstliche Intelligenz befasst. Ein einfaches Beispiel sind Sprachaufnahmeprogramme, die das gesprochene Wort direkt in einen Text umwandeln. Auch digitale Assistenten nutzen NLP um entsprechend vorher definierter Befehle bestimmte Aktionen auszuführen.
NLU – Natural Language Understanding
Natural Language Understanding ergänzt NLP sozusagen um eine Bedeutungsebene. Bei der Anwendung digitaler Assistenten beispielsweise bedeutet das, dass Sie dadurch in der Lage sind, nicht nur auf zuvor definierte Befehle zu reagieren, sondern auch neue Befehle oder alternative Sätze für den gleichen Befehl zu erlernen.
KI überwindet Sprachbarrieren
Diese semantische KI ist auch eine Voraussetzung für gelungene automatische Übersetzungen. Übersetzungsprogramme gibt es schon lange, doch die Ergebnisse sind oft unzureichend. Manche Bedienungsanleitung gibt davon Zeugnis. Die Sprachqualität reicht für journalistische Produkte nicht aus.
KI wird die Qualität automatischer Übersetzungen dramatisch verbessern. Im Idealfall merkt man einem übersetzten Text nicht mehr an, dass er ursprünglich in einer anderen Sprache geschrieben wurde. Das eröffnet den Medien neue Optionen. Zum Beispiel wären Kooperationen wie die Leading European Newspaper Alliance über Sprach- und Ländergrenzen hinweg sehr viel einfacher möglich als heute.
Wenn ein in Deutsch verfasster Beitrag ohne nennenswerten Zeitverzug auch in Französisch, Schwedisch oder Englisch vorläge, könnte er parallel bei Partnermedien in den entsprechenden Ländern erscheinen. Das würde Kosten senken und in kleineren Märkten Produkte ermöglichen, die vorher nicht finanzierbar gewesen wären. Das publizistische Spektrum würde breiter.(1) Da der Text selbst auch als Trainingsdatei fungiert, werden solche Übersetzungen präziser, je länger der Text ist, da dadurch der Kontext für die KI immer deutlicher wird. //
Quellen:
(1) Losau Norbert, Wie Künstliche Intelligenz die Medien verändert, S.4 ( https://www.kas.de/documents/252038/3346186/Wie+künstliche+Intelligenz+die+Medien+verändert.pdf/442f9873-a792-8e4d-cff3-3f2c5e59c9bb?version=1.0&t=1543223168579), CC BY-SA
Quellen:
https://www.cs.uni-potsdam.de/ml/teaching/ws11/ml/Entscheidungsbaeume.pdf, Seite 10
http://www.neuronalesnetz.de/downloads/neuronalesnetz_de.pdf, Seite 28
https://dbs.uni-leipzig.de/file/Straetz_Ausarbeitung.pdf
https://towardsdatascience.com/multi-layer-neural-networks-with-sigmoid-function-deep-learning-for-rookies-2-bf464f09eb7f
Bild / Quelle Abb. 1: https://www.cs.uni-potsdam.de/ml/teaching/ws11/ml/Entscheidungsbaeume.pdf
Bild / Quelle Abb. 2: http://www.neuronalesnetz.de/downloads/neuronalesnetz_de.pdf, Seite 28
Bild / Quelle Abb. 3: https://towardsdatascience.com/multi-layer-neural-networks-with-sigmoid-function-deep-learning-for-rookies-2-bf464f09eb7f
